0x01B - Differential privacy 🎭
👉
Brought to you by:
- WorkOS: the modern identity platform for B2B SaaS. It provides easy-to-use APIs for auth, user identity, & enterprise features like SSO and SCIM.
- Want to improve your product skills? PostHog has created a newsletter for you, check it out here.
- WorkOS: the modern identity platform for B2B SaaS. It provides easy-to-use APIs for auth, user identity, & enterprise features like SSO and SCIM.
- Want to improve your product skills? PostHog has created a newsletter for you, check it out here.
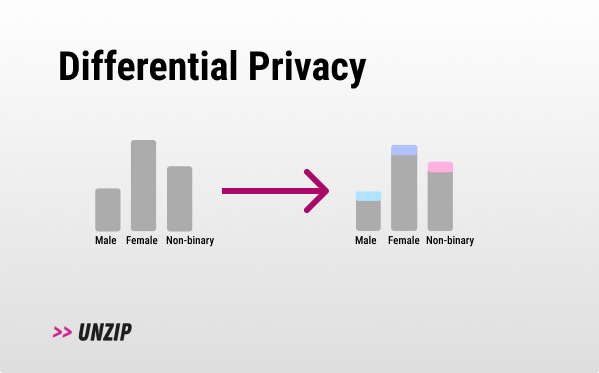
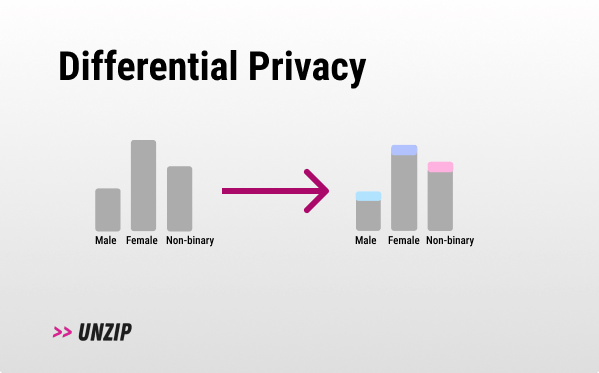
Differential privacy
Differential privacy isn't new, but it's gaining attention as large language models (LLMs) become more prevalent. LLMs can leak sensitive data used in training, even without fine-tuning, raising privacy concerns. Let’s explore it together.
✅
Who is this for?
- Data scientists and ML engineers working with sensitive data
- Privacy advocates and compliance officers
- Anyone building applications handling personal information
- Data scientists and ML engineers working with sensitive data
- Privacy advocates and compliance officers
- Anyone building applications handling personal information
TL;DR:
- Problem: Getting insights from sensitive data while keeping individual privacy is tricky.
- Solution: Differential privacy is a mathematical concept that allows for the analysis of sensitive datasets while protecting the privacy of individuals. It guarantees that no individual's information can be deduced from the result of the analysis.
- In Sum: More data + more privacy rules + increasing need for privacy = differential privacy is becoming a must-have.
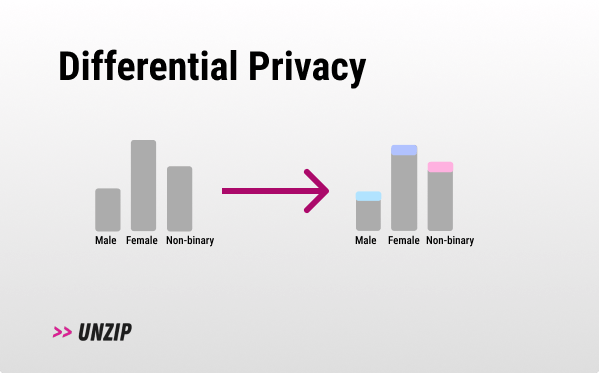
How does it work? 💡
Differential privacy (DP) works by adding a small amount of noise (see Laplace Mechanism) to the result of our query (e.g. a bit of noise to a mean query result). This process guarantees that one person's inclusion or exclusion in the data barely impacts the results, preventing the identification of individual information from the combined data. In other words, if you were to remove one individual from the dataset, you would get the same end result.
There are two approaches to DP:
- Local DP: Adding noise to the data itself (Apple uses it for example).
- Central DP: Adding noise to query results (what most databases/libraries do).
Here is a more concrete (Central) example:
Imagine a company that reveals its average employee salary annually. One year, an employee leaves the company. If you know the average salary before and after the employee's departure, you can easily determine that individual's salary.
To prevent this, differential privacy adds noise to the reported average salaries. By slightly modifying the averages, it becomes impossible to infer any single employee's salary.
Furthermore, when a company has many employees, each individual's salary has a minimal impact* on the overall average. As a result, the noise added to the average salary to protect privacy can be relatively small, preserving the data's usefulness while safeguarding individual information.
DP provides us with a mathematical formula to strike that balance. Check Google’s visual approach or, for a more hands-on approach, read Tumult Analytics’ Getting Started guide.
* - Unless, for example, the CEO has an outsized salary, and then we bound it, so it won’t skew the average-query results too much.
Questions ❔
- Why can’t I just remove PII and call it a day? Removing PII is a good start, but it doesn't protect against re-identification attacks that can still identify individuals from the remaining data - see Netflix and NYC’s Taxi trips debacles.
- How is DP different from traditional anonymization techniques? Traditional anonymization might not protect against all forms of data re-identification (see here also). DP provides a mathematically proven guarantee of privacy.
- Can DP be applied to all data types? Yes, it's flexible and can be adapted to different types of statistical queries and ML models (text, image, etc…).
- What about k-anonymity and l-diversity? Both are still prone to attacks that DP mitigates. They lack the mathematical guarantees DP has.
- Central DP vs Local DP: Local DP is great because you don't need to assume that there is a trusted curator (might come at a cost in accuracy, but that’s changing), on the other hand, most libraries and DBs use Central DP. Read more here.
Why? 🤔
- Standardization: DP provides a standardized approach to privacy that can be universally applied across different datasets and domains.
- Unlock insights: DP lets you analyze and learn from sensitive data without compromising individual privacy.
- Measuring privacy: ε and δ (numeric bounding values) can define privacy in quantitative terms instead of leaving it to legal interpretation or personal opinion.
- Large datasets: DP enables you to use larger datasets that would be off-limits otherwise. For example, DP enables you to use logs older than the standard 90-day retention policy, as long as the epsilon is small enough.
- Future-proof for regulation: The White House and NIST have already hinted that DP might be more prevalent (or even a requirement) in the future. American Census statistics are released with DP, for example.
Why not? 🙅
- Potential Overhead: Added implementation deployment complexity. You must define - mathematically - and understand in depth what privacy means to you and your users, as it differs from one situation to another.
- Configuration: Tuning the privacy-utility tradeoff is tricky. DP is like cryptography, you don't want to roll your own, use a well-maintained library instead. If you mess up the implementation (it's still software), you could compromise privacy without realizing it, unlike a UI bug - you might want to check something like DP-Auditorium.
- Low value: DP might reduce data utility too much for some use cases. Make sure to communicate any uncertainties in the data analysis to relevant stakeholders and users.
- Regulation: Concrete guidance on DP for GDPR and HIPAA compliance is hard to find (trust me, I searched). You might need to lawyer up to ensure you're in the clear.
- Inaccuracy in small datasets: DP shines with large datasets. With small datasets, the added noise can skew results too much.
- Privacy != security: DP doesn’t protect against data breaches, it ensures that the participation of any specific individual is not disclosed as part of the analyzed data.
Tools & players 🛠️
- DP libraries for statistical aggregates: OpenDP (Harvard), PipelineDP built on top of PyDP, Tumult Analytics, Privacy on Beam, Google's DP library.
- DP ML libraries: TensorFlow Privacy, PyTorch Opacus, IBM’s DP library.
- Google / Apple: Both companies use DP, Google for traffic in Google Maps, and also for Chrome’s malicious pages.
- AWS Clean Rooms & GCP’s Clean Rooms: Secure environments for analyzing sensitive data with built-in DP capabilities.
- PVML: Analyze data from multiple sources using DP techniques.
- Syft: Query data without actually getting a copy of it (uses DP under the hood).
- Sarus: YC-backed company focused on DP for AI use cases and their SDK.
- Tumult Labs: A DP startup with a Python platform using Apache Spark.
- Immuta Privacy: A set of privacy tools including DP features.
🤠
My opinion: I don't think my opinion carries much weight here, as this stuff is a bit above my pay grade ;) But generally speaking, I'd stick with the official docs of your training framework (TensorFlow/PyTorch) when implementing DP.
Forecast 🧞
- LLM Privacy: The whole reason I got into this topic is that I'm seeing a growing need for keeping private data out of LLMs. It's a hot issue right now - see Extracting Training Data from LLMs.
- Baked-in support: As privacy becomes more and more important, I expect to see tools (especially DevTools) that have privacy features built right in. It should become the norm, not the exception.
- Regulation: I wouldn't be surprised if we see more laws and regulations specifically addressing differential privacy in the near future. As DP gains traction, expect regulators to provide clearer guidance on how it fits into existing privacy frameworks like GDPR and HIPAA.
- Internal company policies: Looks like big tech companies are jumping on the DP bandwagon and being proactive about privacy. We might see a big push from internal policies in these companies spreading to the rest of the industry. The Gboard models requirement is a great example. Adding DP to your skill set could be a smart move.
- Integration with other privacy tech: DP will probably be increasingly used in combination with other privacy-enhancing technologies like secure multi-party computation.
Extra ✨
Additional information that is related:
- Deep Learning and differential privacy.
- A friendly introduction to differential privacy.
- Local differential privacy & Federated learning, run all the DP work locally and then share the results.
- DifferentialPrivacy.org, a nice resource for differential privacy (mainly for the academic research community).
- Randomized responses as a form of DP.
- Have your data and hide it too, a nice recent blog post from Cloudflare.
- Real-world uses of differential privacy.
- DP-SGD, Differentially private stochastic gradient descent. Adding noise to the gradients during the training process - allows us to train deep models with some privacy guarantees- implemented by multiple libraries (TensorFlow Privacy and Opacus).
- How to protect your private data when fine-tuning LLMs.
Thanks 🙏
I wanted to thank Damien Desfontaines (Staff Scientist at Tumult Labs and expert for the European Data Protection Board), Pierre Tholoniat (Ph.D. Student in Computer Science, Columbia University researching security and privacy), Luca Canale (Senior ML Research Engineer at Sarus), TomGranot (who edits every issue, and owns a TPM - Technical Product Marketing - consultancy for deep-tech startups), …
EOF
(Where I tend to share unrelated things).
Any dev trends you'd like me to cover next? Just reply here, I answer every email.