0x013 - io_uring 🦑
Get more 5-minute insights about dev trends every 3-4 weeks. To subscribe you need to code your way there via the home page (or the easy way here)...
io_uring
✅
Who is this issue for?
- Low-level developers.
- You care about optimizing Linux IO operations.
- Low-level developers.
- You care about optimizing Linux IO operations.
TL;DR:
- Problem: Syscalls are expensive…
- Solution: An I/O model that works uniformly across all file types (!) that provides a general-purpose syscall batching mechanism, which cuts down on context switches and syscalls.
- In Sum: Other than exposing a better async I/O interface, the ideas behind io_uring might change mindsets and thus abstractions across the board (language runtimes, and frameworks).
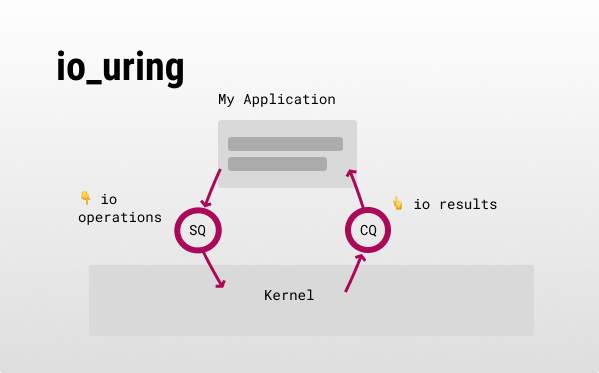
How does it work? 💡
I highly recommend you read this excellent intro about io_uring.
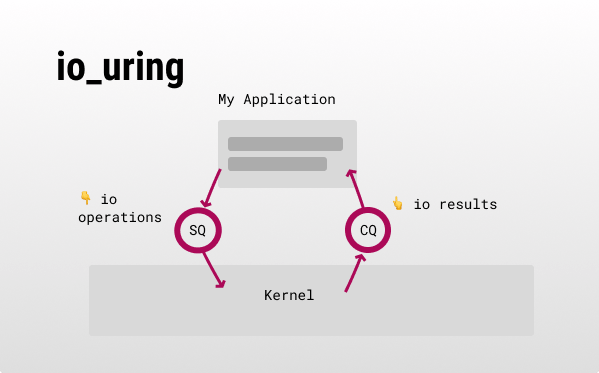
Now some implementation details: io_uring has 2 ring buffers,
- Submission queue (SQ): for submitting an I/O operation.
- Completion queue (CQ): for the result (data and status) of that I/O operation.
Both buffers are shared between the kernel and userspace to boost IOPS, as there is no need to copy these buffers back and forth (reduces syscalls).
In a very high-level overview, using io_uring (via liburing) consists of 4 main steps:
- Setup: decide how io_uring will run under the hood (optimize based on your workflow).
- Setting up your I/O operations (called SQEs, and their opcodes).
- Submission: Let io_uring know you want it to process your SQEs (can skip this step, a syscall, if you are polling with SQPOLL).
- Waiting for your async I/O operations to complete.
P.S. as Glauber Costa told me, if you have lots of very small reads, where the cost of servicing IRQs is high, using IOPOLL mode can be a game changer.
Now you can batch what would typically be separate syscalls into a set of operations that the kernel consumer will run for you - eliminating a whole lot of context switches and syscall overhead.
Questions ❔
(New section, I'll use here and there)
- What is the difference between io_uring and epoll?
- Both are great for async networking. But, epoll doesn’t do I/O, just a “readiness indicator” that works on a subset of files (eg pipes, sockets, and anything pollable). With Linux 5.5 io_uring started to introduce network-related methods, so io_uring isn’t limited only to networking syscalls like epoll. It also seems like io_uring can be more performant.
- Is this the first async interface out there? No - read about POSIX AIO (glibc userspace ), libaio…
- What’s the difference? There are older solutions that have several limitations, which io_uring elegantly overcomes.
Why? 🤔
- Shorter CPU cycles: No need to block in userland, fewer context switches.
- Parallelism enabling: The async nature of io_uring enables parallelism, as new operations can be issued before the last one completes. Don’t forget the built-in lock-less communication. This means that your applications can run without being blocked.
- Hardware utilization: Improving hardware utilization - the affinity of each thread can be decided per the relevant hardware.
- Nice developer experience.
Why not? 🙅
- Order is not guaranteed: Because of the nature of async operations, the result can come in a different order than sending the operation. There could be overhead to track the order when necessary - although you could use IOQSE_IO_LINK.
- Redesign: The cost of resigning systems to adhere to the io_uring async nature could prove costly - it’s a mind shift.
- Potential security misbehaviors: io_uring didn’t address some key security concerns when it came out, and by the nature of it there might be inconsistencies arising in the future too - this is more relevant to SecOps people who configure io_uring in production.
- Linux 5.1 and up: You won’t have any io_uring interfaces before that kernel version.
- epoll might still be faster? See this conversation.
Tools & players 🛠️
- liburing - The io_uring library.
- Jens Axboe - io_uring is his brainchild.
- cachegrand - A modern k/v store utilizing io_uring.
- Dragonfly - A modern replacement for Redis and Memcached.
- plocate - A faster locate (using io_uring).
🤠
My opinion: If you’re working on some heavy I/O-bound software, consider looking for tools, libraries, and language runtime bindings that utilize liburing - or even use it directly. If you are already using AIO and you aren’t here to squeeze every last bit of performance, the transition to io_uring might not be super critical.
Note: I'm not a kernel developer, so you might want to form your own opinions on the matter ;)
Note: I'm not a kernel developer, so you might want to form your own opinions on the matter ;)
Forecast 🧞
- Hidden Performance Boosts: I can see how FS I/O operations become faster in the underlying systems and libraries many of us use, causing systems that rely heavily on filesystem access like ETL pipelines, media processing jobs, CI agents, web servers, and databases to (almost magically) increase their overall performance.
- Faster systems = simpler DX: With faster I/O some data structures and caching mechanisms might not be as necessary as before.
- eBPF: By wielding the power of eBPF we can have more control without needing to directly access the kernel - meaning we can do many more things from user space only (empowering for tooling and debugging).
- io_uring might be undersold? Not just “async io” but a general-purpose syscall batching interface (which could result in cross-platform adoption → making it easier to do high-performance IO everywhere, OS as Actor Model?) and become a universal interface for all communications with the kernel.
Examples ⚗️
Who uses it? 🎡
- QEMU, libuv, Samba, uWebSockets…
Extra ✨
Additional information that is related:
- Awesome-iouring - links to relevant tools, libraries and information.
- The man page.
- “Lord of the iouring” kind of like the wiki-bible of io_uring from what I see.
- The missing io_uring manuals (interesting deep-dive read).
- io_uring and ebpf - a great intro including eBPF.
- A nice, clean presentation or video about new things in io_uring (by the creator).
- The Technium Podcast about io_uring.
- IoRing (windows) vs io_uring comparison.
- Performance (and Meltdown reference).
- io_uring and networking in 2023.
- And this got to the top of HN a few hours before I sent you this issue ;)
Thanks 🙏
It's pretty crazy, but Jens Axboe (the creator of io_uring) was super nice and reviewed this issue (!) - Jens, if you read this, thank you again! you rock ❤️ Other reviewers I wanted to personally thank: Glauber Costa (Founder/CEO at tursodatabase and maintainer libsqlhq), Roy Feldman (One of the smartest & nicest people I know, currently building and teaching infosec workshops), Naim (a dear friend, security researcher and Rust enthusiast). And of course, last but not least, Tom Granot (the best growth person I know).
EOF
(Where I tend to share unrelated things).
- Tom and I started a YouTube channel for digital business ideas we don't have time to make - so we're giving them away. We don't shy away from the technical dev aspects so I think you might like it. We call it Up for Grabs. You're welcome to subscribe if you want to see us blabbering 😂