0x00B - Stable Diffusion 🖼️

Welcome to unzip.dev, a newsletter dedicated to unpacking trending developer concepts. My name is Agam More, and I’m a developer generalist. I’ll be posting every few weeks, so if you haven’t subscribed yet, go for it!
The results of the survey are out. This issue was released quite quickly, so I didn’t get time to properly insert sponsors. The next issue can be sponsored by your company - reply to this email for details.
Stable Diffusion
Also known as Latent Diffusion Models.
This issue is a blitz issue. I see this trend taking prominence quite quickly, and I didn’t want to leave you hanging for the weekend.
TL;DR:
- Problem: Creating art by hand is hard, and using closed-source generative art is only open to a minority group.
- Solution: An open-source version of DALL-E that generates images automatically from text prompts, which you can run at home.
- In Sum: The democratization of generative art open to the public will transform how we use and perceive creative work.

How does it work? 💡
- Scraping the internet for more than 5B image and text pairs (dataset: LAION-5B).
- Training with a stable diffusion model (see detailed under-the-hood).
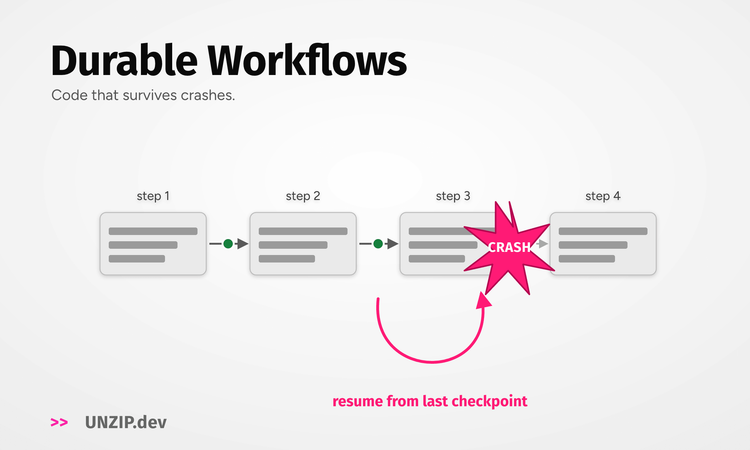
a. The basic idea is to take an image and add a little bit of noise.
b. Every time you add noise, you ask the model to learn to denoise the image back to the less noisy version. - The model is compressed to a few gigabytes.
- When using the model:
a. The model creates an embedding representation of the prompt you enter.
b. It is fed into the diffusion model with some random pixel noise.
c. The model denoises it towards the embedding many times.
d. Lastly, the image is upscaled to a 512x512px image.
Explanation summarized from Marc Päpper.
Use cases ✅
- Marketing
- Digital art
- Hobbyists
Why? 🤔
- Open-source: tinker with the model’s internals, and see how it works. Create your own offline private model.
- Permissive License: allows for commercial and non-commercial usage. See license here.
- No limits on creations: DALLE-2 limits your results. With an open model, you can produce whatever you want.
- Efficiency: Stable diffusion is much more efficient than DALLE-2. It can run on a consumer GPU card, needing only around 10 GB of VRAM (!)
Why not? 🙅
- Biases: the model was trained on scraped data from the internet so biased results might be present - be careful.
- Quality: the quality might be subpar to DALLE-2 at the moment. You will also want to feed the result to an upscaler in most cases (something like Real-ESRGAN).
- Precise: It takes a while to get a picture that somewhat resembles your prompt. Very specific art requirements might be still more relevant for human work (like making sure an element is present and designed correctly).
Tools & players 🛠️
- Model code and weights on HuggingFace & GitHub from Stability.ai.
- Official Stability.ai’s Discord.
🤠
My opinion: you basically have an on-demand concept artist that can generate anything you can imagine for almost free. See the forecast for more thoughts.
Forecast 🧞
- Mass adoption
- Marketing: generating blog thumbnails and photos - which will be free of copyright (Programmatic SEO anyone?)
- NFTs: now you can produce massive amounts of digital art which goes hand-in-hand with NFTs.
- Advertisements: creating mass amounts of ad creative and a/b testing them can be done at scale.
- Better looking: right now it seems like DALLE-2 produces slightly better results, but I can see this changing relatively quickly.
- Ethical concerns: Producing unethical images like deepfakes can be a serious problem. Also, over time, producing images that are realistic enough could make it hard to rely on images for legal judiciary evidence.
- Copyrights: having similar to original pieces of artwork might become copy-right free, rendering artwork copyright irrelevant.
- Videos and 3D models: videos and 3d models are just a bunch of images. I can see how we get models that produce videos soon. Imagine creating movies from some text idea? Maybe someone could finally create new seasons for Firefly? I can also see this impacting video game creation.
- UI/UX: mocking UI/UX experiences could be done relatively easily now. I can see tools targeting this niche.
- Employment ripples: I’ve already seen some artists raising concerns about these models. I can assume that lower-end art creators will have a hard time competing with these models unless creativity and special stylistic designs are needed.
Examples ⚗️
Try it out yourself?
- Google collab you can play with.
- DreamStudio (beta) - a stable diffusion playground - requires social login.
- The DALLE-2 subreddit is a great source to learn more about generative art and prompts.
Extra ✨
Additional information that is related to the subject matter:
- Copyrights on generative art?
- Prompt book for DALLE-2.
- Using stable diffusion to compress images?
- Exploring the training data.
- Img2img example - I used this several times for the issue image.
- AI-Generated Artwork wins art competition.
Thanks 🙏
Wow, this issue was created super quickly. I'm really lucky to have people respond quickly to check it out. People: Elad Ben Arie (Data & Applied Scientist at Microsoft | CS M.Sc. student at TAU), Roee Shenberg (doing some amazing AI stuff), Tom Granot (The best DevRel I know), Alon Malin (a great presentor and writer).
EOF
(Where I tend to share unrelated things).
I managed to create some Unzip stickers. Wanna see what they look like?
If you want to print your own - reply to this email, and I’ll send you the .ai file.
Any questions, feedback, or suggestions are welcome 🙏
Simply reply to this e-mail or tweet at me @agammore - I promise to respond!