0x006 - Large Language Models 🦣
Hi, y’all! This is the sixth issue of unzip.dev, a newsletter dedicated to developer trends, where we unpack trending dev concepts. My name is Agam More, and I’m a developer generalist. I’ll be posting every few weeks, so if you haven’t subscribed yet, go for it.
A HUGE shout-out to all the new subscribers from HN. Seeing the replies flooding my inbox was… priceless. It's so important to know that you're not just shouting into the void - there are actual people on the other side who read, enjoy and give great feedback on my stuff. The internet is truly an amazing place 😍
(Hosted) Large Language Models
Synonyms: LLM, GPT-3, Transformer-based NLP models, (& few-shot learning).
Note: In this article, I’m mostly referring to API usage of hosted models, and not hosting or building models in-house.
TL;DR:
- Problem: Computers can’t perform natural language tasks easily.
- Solution: Train deep neural networks at scale, so they could simulate a human-like understanding of textual problems.
- In Sum: Large language models are already used in production, enabling new businesses & technical solutions. They are still very costly to create and can impose ethical risks.
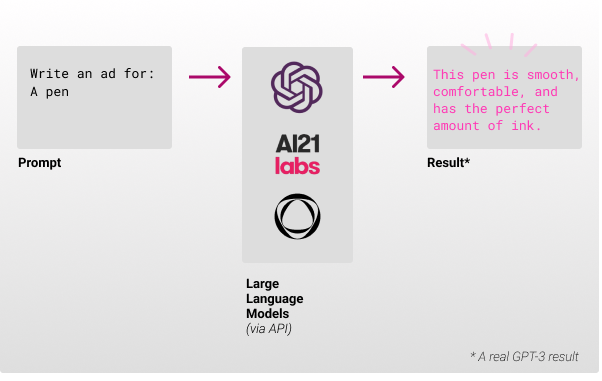
How does it work? 💡
- A company invests considerable amounts of money (e.g. GPT-3 cost $4.6M) into generating an LLM (large language model). You can read more about how they are created: white paper or article.
- They export an API you can use.
- (Optional) You can decide to fine-tune the model before using it.
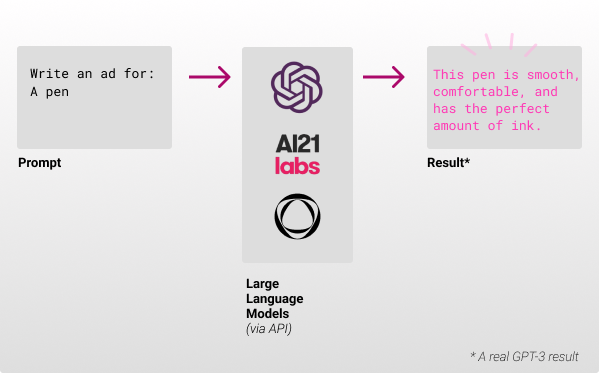
- You send a prompt (the input text for the model) which contains a few examples and one partial example, so the model can complete it.
- (Optional) Send parameters to tweak the results, like temperature (which controls randomness) and others.
- In some cases you can also make the model work without examples; this is called zero-shot.
- You get back a result with the probabilities of each word generated by the model.
Use cases ✅
- Solve hard natural language tasks.
- Companies that don’t have resources for a fully-fledged ML team and need to solve a hard NLP problem.
Why? 🤔
- Solve difficult problems: Some tasks large language models can perform are mind-boggling and were not possible only a few years back without a team of researchers and manual labor.
- Text generation, classification, summarization, rewriting, translation, question answering, sentiment analysis, and more...
- Fast and easy to use: Because most of the models are very costly to train, you just use an API to get the results, and the learning curve to start using the models is relatively easy.
Why not? 🙅
- Cost: These models are priced by usage, which can get very expensive very fast (see GPT-3’s pricing). Not to mention the sustainability of generating the model and ethical questions that may arise, such as replicating bias that exists in the training data.
- Can’t solve everything: Current models can’t solve every problem correctly, but it might still be interesting to try. Most large language model APIs have a limit on input and output sizes.
- Sensitive data: Because your data is sent to an external API, sensitive data and on-premise scenarios won’t benefit from these models easily.
- Might be overkill: Sometimes the cost of an LLM via API is not needed: if you need basic text summarization, for example, there are already small pre-trained models and techniques that do a good (enough) job.
- Consequences: A bad result could be costly (like this one).
Tools & players 🛠️
- GPT-3 Playground - OpenAI’s web interface to interact with the GPT-3 Model.
- AI21 Studio - A playground similar to the GPT-3’s playground.
- Hugging face - Community effort to build, train and deploy state-of-the-art models.
- EleutherAI - A volunteer collective that builds open-source LLM models.
🤠
My opinion: Assuming you don’t have the know-how or the money to train your own model, I would look at GPT-3 or AI21’s J-1. For ease of production deployments, I chose J-1 (pricing and no strict approval like GPT-3 - see the Examples section). For coding specific tasks, I’d go with Codex (Future issue).
Forecast 🧞
- New possibilities: As more developers become familiar with the capabilities of LLMs, we will see more and more advanced software solutions and problems that would need a human might be done by a language model. Larger models may open up even more possibilities that are currently difficult to even conceive of.
- Real-world data: Some impressive advancements were made by the team at AI21, releasing Jurassic-X, it can incorporate real-world data into the result, so for example it will answer that Biden is the president and not trump (like GPT-3 currently does). They are not bound by their training data. I can see how most models will transition to this kind of methodology. Try it out here.
- Fine-tuning: Refining prompts and fine-tuning the models can boost their accuracy. I can see external players democratizing this “black magic” to less specialized developers. For example, better prompts generation, or a SaaS to handle fine-tuning models.
- Video & Audio: DALL·E 2 already shows amazing image results, and needless to say, videos are just a series of images. It might be interesting to see what can be done in the video & audio space (will we have full movies or games generated by a description?)
- New roles: We can already see people specializing in prompt engineering, and as this concept grows I suspect we will see more brand-new roles created to better interact with these powerful tools. It is also theorized that we will lose jobs to large language models.
- Optimizations: We can already see some advancements that reduce the cost and computation power needed to create LLMs. Over time, it seems like the process of building models might be commoditized.
- LLM Management: I can easily see more tools to manage LLMs, stitching large prompts together (there are strict limits in the base usecase), provide cost estimations and all the necessary tools to manage an LLM project.
Examples ⚗️
Interesting to mention, but I used GPT-3, and then AI21’s J-1 models in production at my last job. We had a lot of engineers wasting time documenting JSON responses from REST APIs, so I thought of automating those tasks. The code is here - it was a super cool project (including fine-tuning, log probs, and hacky error correction).
Who uses it? 🎡
Microsoft, The Guardian, Viable (Blog), Algolia (we covered them in 0x002), Salesforce...
Extra ✨
- GPT-3 Demos, gptcrush, and applications for GPT-3 and awesome-gpt3.
- Documentation: OpenAI’s GPT-3 docs, AI21’s Studio docs.
- The New York Times has recent coverage of OpenAI: long-form article, podcast.
- Create your own transformer.
- Advanced Prompt Design for GPT-3 (check out @AndrewMayne’s blog for more GPT-3 related content).
GPT-3 In action, a summary of the next https://t.co/3fAmebMoge issue about Large Language Models. @unzip_dev pic.twitter.com/XP0Gn7K1qT
— Agam More (@agammore) April 25, 2022
Thanks 🙏
I wanted to thank Tom Granot (the best DevRel I know), @Leeam332 (edited the heck out of this issue, plus, she talks about human rights and tech, and she is my lovely sister).
EOF
Many developers like me are working for a SaaS company or want to create one - why not learn more about it? A recent newsletter I came across is SaaS Weekly. They send out only a few curated SaaS-related links every week. Go check them out :)
Any questions, feedback, or suggestions are welcome 🙏
Simply reply to this e-mail or tweet at me @agammore - I promise to respond!