0x014 - Vector Databases 🧫
Get more 5-minute insights about dev trends every 3–4 weeks. To subscribe, you need to code your way there via the home page (or the easy way here)...
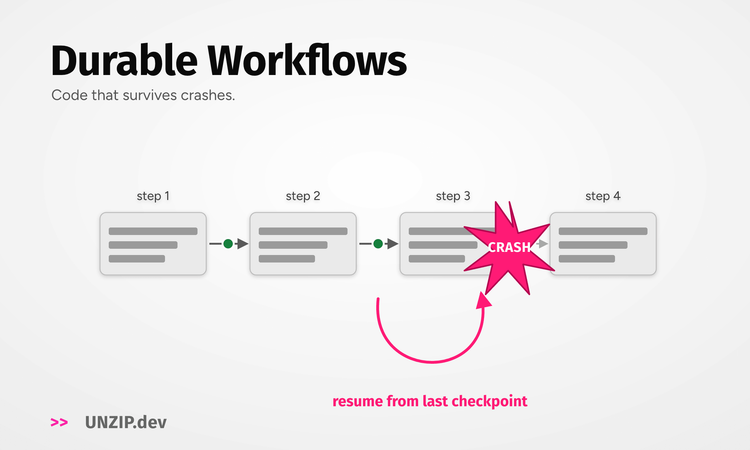
Vector Databases
Synonyms: Embedding databases, vector similarity search engines.
✅
Who is this for?
- Developers using LLMs.
- Industries: Bioinformatics, Data Science, Search Engines, Computer Vision, Recommendations, Anomaly detection, Chatbots, and many more…
- Developers using LLMs.
- Industries: Bioinformatics, Data Science, Search Engines, Computer Vision, Recommendations, Anomaly detection, Chatbots, and many more…
TL;DR:
- Problem: Advancements in semantic understanding of unstructured data created a treasure trove of meaningful data. But traditional databases cannot efficiently store and query these semantic records (large vectors).
- Solution: Vector databases specialize in storing high-dimensional vectors, providing efficient querying mechanisms based on vector similarity rather than traditional relational queries.
- In Sum: Vector databases will be an essential part of any serious AI application. Over time, we will probably see a consolidation of DBs.
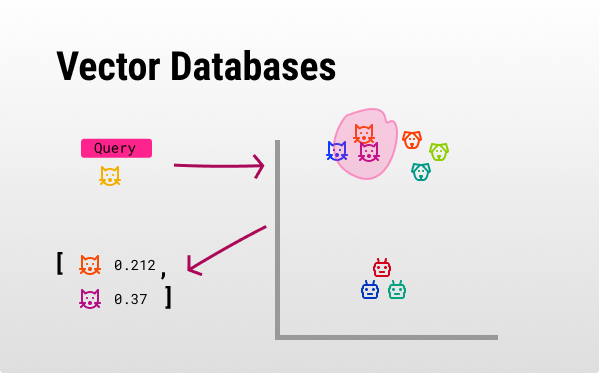
How does it work? 💡
First, let’s get on the same page about embeddings (high-dimensionality vector representations of words, sentences, images, audio…) [1, 2]. They are supposed to hold semantic information about your input data.
Because of advancements in LLMs the embeddings we get have a better “understanding” of your text. This means that querying for the similarity between those vectors produces much better semantic results than before [3, 4]. But, we need to store those valuable vectors somewhere and query them - that’s where vector databases come in.
Vector databases use algorithms like ANN (Approximate Nearest Neighbors) so they can facilitate efficient storage, retrieval, and similarity search operations, rather than relying on exact match or range queries. This is especially important for recommendation systems or semantic search, where the nearest or most similar items are as valuable as exact matches.
An example
Let’s say we wanted to ask questions about the book “The Mythical Man Month” by Fred Brooks.
In an ideal world, we would add all of the book’s content to our prompt*. But, LLMs have a limited character limit (e.g. 8k in GPT 4), on top of that, the more tokens you use, the higher costs you incur.
One solution might be to extract smaller relevant sections from the book, so we could add only them to our prompt.
So we split the book into sections (could be paragraphs) and generate their embeddings, add the relevant metadata like the original text and store them in our Vector DB of choice.
Now we generate an embedding to our question. Then we ask the vector DB to find the 5 closest embeddings to our question's embedding. We then append the original texts of those embeddings into our prompt - giving us better context for our question.
*Note: From personal experience, a smaller focused prompts performs better (might change in the future).
Questions ❔
- Why not use existing RDBMS/NoSQL DB? While these databases excel at handling structured data with a fixed schema, they often struggle with unstructured or high-dimensional data, such as images, audio, and text. Traditional databases have not been designed to efficiently handle the task of searching for similar items in a large dataset, specifically high-dimensional vector data which makes them perform worse at scale.
Why? 🤔
- Long-term memory: Storing information for later use can be very beneficial. By encoding data such as text, images, or audio into embeddings, we can retain their meaning by storing similar data closer to each other. This facilitates better information retrieval and gives your product the ability to persistently retain large amounts of knowledge over time.
- Overcome context size limitation: By leveraging vector databases we can store shorter sections of large data we want in the prompt context. Then we can fetch only the semantically-relevant shorter sections from the vector DB and overcome the token limitation.
- Cheaper than an LLM query: Embeddings generation is relatively cheaper than invoking a full LLM API call. Querying our embeddings against our DB is much cheaper. Embeddings still retain some semantic information about the text, so we could get the best of both worlds.
Why not? 🙅
- No real need: If exact matches, range searches “semi-sematic” queries (lemmatization, stemming, tf-idf, fuzzy queries…) produce a “good enough” result, there is no need to buy into the hype. Generating the embeddings and using a Vector DB cost money. Be smart, not cool.
Tools & players 🛠️
- Pinecone - A managed vector database that is easily scalable.
- pg_vector - Vector similarity search for Postgres.
- Weaviate - Open-source vector database with a hosted solution.
- qdrant - Open-source with hosted availability, with rich data types like images and geolocation.
- milvus - Another open-source vector database (Zilliz - hosted version).
- RediSearch - Redis’s own vector DB module.
- Supabase Vecs - A Python library for managing embeddings in your Postgres database with the pgvector extension.
- More: vespa, chroma, deeplake, scann, vlad, faiss (from meta), elastic (with dense_vector or relevance engine), LangChain (vector stores).
- (Updated): Activeloop (dev-first vector db)
🤠
My opinion: Pinecone seems like one of the most hyped managed DBs out there for embeddings - so for your investors that might be a good reason (I might be slightly sarcastic) - last time I used them the DX was not amazing, but that might change. I would personally use supabase +pg_vector - that way I have zero vendor locking and I can start pretty easily. Otherwise, use whatever DB you already know and add a vector extension, unless you need tons of efficiency and scale from the start.
Forecast 🧞
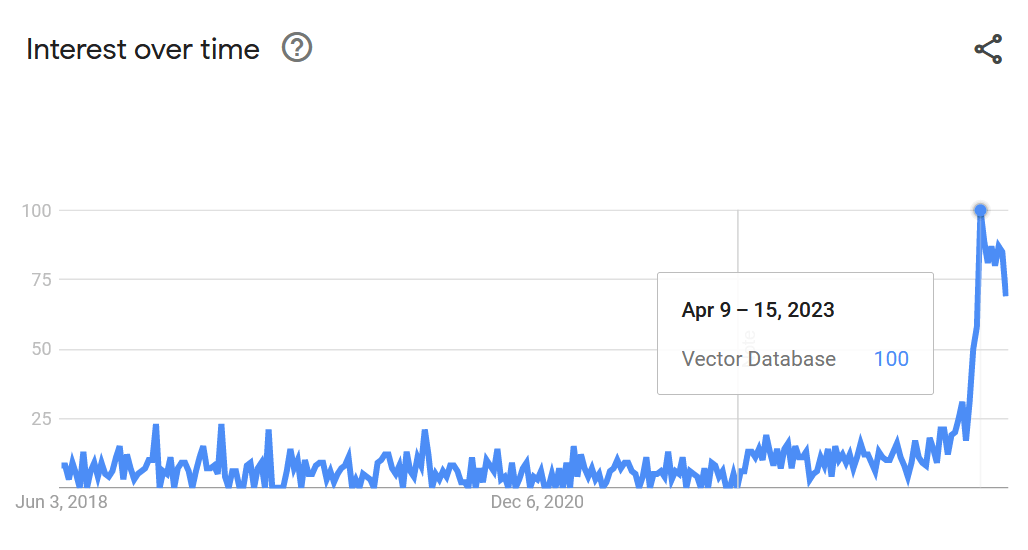
- Hubpot’s Dharmesh Shah’s: forecast and excellent explanation and forecast in the “My first million” podcast.
- Consolidation: The hype of LLMs that sprouted the need for Vector DBs created a gap that many came to leverage. I think that many overvalued investments in this space will turn out badly. The best DX and marketing will consolidate into a handful of players and kill the rest - why would I use a DB that offers the same thing, and it’s less popular or easy to use? Plus, if you already use Postgres, Ealstic, or Redis, why change?
- Better products: Because we are commoditizing vastly better semantic understanding of text, I can see how many products we use today will produce better experiences in places like Search & Recommendations.
- Extensions to traditional DBs: Traditional DBs will most likely want to implement some kind of vector handling too, to be part of the “cool kids” group (like Postgres with pg_vector).
- Better SDKs: Currently, it seems like interacting with Vector DBs is very low-level. I suspect seeing abstraction libraries and SDKs that abstract most of the extra work. . If you’re interested in this - hit reply (I’m working on something open-source here).
- Untapped unstructured data: Vector DBs will allow businesses to use data that was previously untapped. This could lead to new insights and innovations that were not possible before.
Examples ⚗️
- A chroma DB example notebook.
Extra ✨
Additional information that is related:
- Comparisons of major ANN algorithms.
- Supabase’s guide on how they built their documentation AI search (Highly recommended!).
- Fireship’s excellent (and funny) introduction to the topic.
- The Vector DBs CAP Trilemma.
Thanks 🙏
I wanted to thank @TomGranot (the best growth person I know), @AndyKatz (Development of enterprise-grade AI R&D solutions), @Amit Eliav (My go-to for GPT and ML questions).
EOF
(Where I tend to share unrelated things).
I just released Unbug a Free GPT-Powered bug finder for your GitHub repositories. You can self-host it pretty easily and use your own OpenAI key. I’d love to get some love 😘. (WIP)
P.S. This issue took me 14+ hours to compile, I hope you liked it.